MPI Parallelization
In large-scale applications, one often encounters problems that can be parallelized by distributing the calculation of different Green’s functions across different computing ranks. A typical example are lattice simulations, where the solution of the Dyson equation for the Green’s function \(G_k\) on each point \(k\) on a discrete momentum grid can be performed in parallel. The library provides some features for distributed-memory parallelization via MPI:
Member functions of
cntr::herm_matrixandcntr::herm_matrix_timestepallow sending/receiving the data at one timestepA class
cntr::distributed_timestep_arraycan be used to handle all-to-all communication of Green’s function on a given timestep.The class
cntr::distributed_timestep_arrayis derived from a classdistributed_array, which implements an array of data with distributed ownership.
Communicating timesteps
Member functions of A, where A is of type cntr::herm_matrix and cntr::herm_matrix_timestep:
|
Broadcast the data of \(A(t,t')\) on timestep |
|
In place reduction, replacing \(A(t,t')\) on rank |
|
Send the data of \(A(t,t')\) on timestep |
|
Receive a message with tag |
A simple reduction operation:
|
\(A(t,t')\) at |
The type GG of
AandBiscntr::herm_matrix<T>orcntr::herm_matrix_timestep<T>Bmust exist on each rank,Aon therootrank.Size requirements:
AandBmust have equalsize1andntauFor
X=A,B: IfXisherm_matrix, thenX.nt()>=tstpis required; ifXisherm_matrix_timestep, thenX.tstp()==tstpis required.
Example:
In the following example, each rank owns the Green’s function \(G_k\) for one momentum \(k\) out of a given discrete grid of \(N_k\) momenta, which are equidistantly spaced over the first Brillouin zone \([0,2\pi)\) of a one-dimensional lattice. Rank 0 owns a local Self-energy, which is sent to all ranks to solve the Dyson equation:
The data are then collected to compute a local Green’s function \(G_{loc} = \sum_{k} w_k G_k\) on rank 0, with some given weights w_k (which are just w_k=1/N_k in the example).
// MPI is initialized as:
MPI::Init(argc,argv);
int nranks=MPI::COMM_WORLD.Get_size();
int tid=MPI::COMM_WORLD.Get_rank();
int root=0;
int nk=ranks; // Here : # of momentum points = # of MPI ranks
double local_k = (2.0*M_PI/nk)*tid; // momentum kept at the local rank
double wk=1.0/nk;
// allocate Gk and epsilonk with same size nt,ntau,size1,sig on all ranks
GREEN Gk(nt,ntau,size1,sig);
CFUNC epsilonk(nk,size1);
GREEN Sigma,Gloc;
// the variable Sigma and Gloc is allocated only on root:
if(tid==root){
Sigma=GREEN(nt,ntau,size1,sig);
Gloc=GREEN(nt,ntau,size1,sig);
}
// ... do something to initialize function epsilonk at every rank, depending on local_k
// typical simulation loop at timestep tstp (tstp>SolveOrder):
// send Sigma to all ranks:
Sigma.Bcast_timestep(tstp,root);
// Solve dyson equation separately on each rank:
cntr::dyson_timestep(tstp,Gk,mu,H,Sigma,SolveOrder,beta,dt);
// compute the local Green's function at the root, using a temporary variable:
GREEN_TSTP tGk(tstp,ntau,size1,sig);
tGk.set_timestep(tstp,Gk);
tGk.smul(tstp,wk);
cntr::Reduce_timestep(tstp,root,Gloc,tGk);
Distributed timestep array
While the previous example was based on simple root to all reduction and broadcasting operations, calculating lattice susceptibilities and self-energies often requires an all-to-all communication of a set of Green’s functions at one timestep. We provide a class cntr::distributed_timestep_array which is customized for this application:
class |
|
The
cntr::distributed_timestep_array<T>contains an arrayT_kofnherm_matrix_timesteps (each with the sametstp,ntau,size1andsigparameters, see Timeslices), which are indexed by an indexk\(\in\{\)0,...,n-1\(\}\).kcan be, e.g., a momentum label for lattice simulations.The full array is accessible at each
MPIrank, but each timestepT_kis owned by precisely one rank (a vectortid_map[k]stores the id of the rank which owns timestepk). Typically, each rank first performs local operations on the timestepsT_kwhich it owns. All timesteps are then broadcasted from the owning rank to all other ranks, so that finally each timestepT_kis known to all ranks.
Important member functions of cntr::distributed_timestep_array<T>:
|
Constructor. |
|
Returns |
|
The |
|
Returns rank id ( |
|
All data set to |
|
Return |
|
Return a handle to the timestep of index |
|
Broadcast timestep \(T_k\) from its owner to all other ranks. |
|
Broadcast all timesteps from their owner to all other ranks. |
|
A way to return the vector |
|
Returns a handle to an underlying |
Note
In the implementation, the distributed_timestep_array is not an array of cntr::herm_matrix_timestep<T> variables, but a sufficiently large contiguous data block and an array of shallow cntr::herm_matrix_timestep_view<T> objects. This allows for an easier adjustment of the size of the timesteps. The herm_matrix_timestep_view<T> object has the same functionality as the herm_matrix_timestep (see Overview).
Example:
The usage of the distributed_timestep_array can be understood best by means of an example. In the example below we consider a vector (std::vector<GREEN> Gk) of momentum-dependent Green’s functions \(G_k\) on a grid of nk=6 momenta (k=0,...,5). The memory-intensive Green’s functions should be distributed on ntasks=3 MPI ranks, such that each \(G_k\) is available only on one rank. One can use a distributed_timestep_array object TARRAY to make a given timestep of all Gk available to each rank:
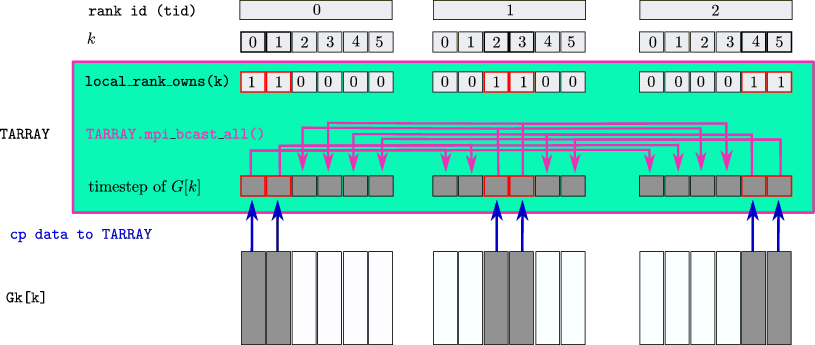
The
distributed_timestep_arrayspecifies whichkis owned by which rank.The vector
Gkis available at each rank, but at a given rank memory forGk[k]is only allocated ifkis owned by that rank (i.e., ifTARRAY.rank_owns(k)==true).Each rank can perform local operations on its own Green’s functions
Gk[k], and then copy the data of a given timesteptstpto theTARRAYThe global
MPIoperationTARRAY.mpi_bcast_all();then makes all timesteps visible to all ranks.
// MPI initialized with ntasks=6 ranks, local rank has rank-ID tid
int nk=6;
// ... set nt,ntau,size1,sig ...
GREEN Gloc(nt,ntau,size1,sig);
std::vector<GREEN> Gk(nk);
cntr::distributed_timestep_array<double> TARRAY(nk,nt,ntau,size1,FERMION,true);
for(int k=0;k<nk;k++){
if(TARRAY.rank_owns(k)){
cout << "rank " << tid << " owns k= " << k << endl;
Gk[k]=GREEN(nt,ntau,size1,sig); // allocate memory for full Green's function Gk only on ranks which own k
}else{
cout << "rank " << tid << " does not own k= " << k << endl;
}
}
// typical simulations at a given timestep:
TARRAY.reset_tstp(tstp);
for(int k=0;k<nk;k++){
if(TARRAY.rank_owns(k)){
// ... rank owns k, do some heavy numerics on Gk[k]
// then copy timestep to TARRAY:
TARRAY.G(k).set_timestep(tstp,Gk[k]); // read in data from Gk[k] to the array
}
}
TARRAY.mpi_bcast_all();
// now on all ranks and for all k TARRAY.G(k) contains the data of Gk[k]
// this can be used, e.g., to calculate a local Green's function:
Gloc.set_timestep_zero(tstp);
for(int k=0;k<nk;k++) Gloc.incr_timestep(tstp,gk_timesteps.G(k),1.0/nk);
// or do more complicated stuff, such as calculating a self-energy diagram with internal k summations
Distributed array
class |
|
The
cntr::distributed_array<T>contains an array ofnequally sized data blocks, each containingblocksizedata of typeT, which are indexed by an indexk\(\in\{\)0,...,n-1\(\}\). All data are stored contiguous in memory.The full data set is accessible at each MPI rank, but each block is owned by precisely one rank (a vector
tid_map[k]stores the id of the rank which owns blockk).MPIroutines are used to send the blocks between ranks.
Important member functions of cntr::distributed_array<T>:
|
Constructor. |
|
The number of elements in each block is set to |
|
Returns |
|
Returns rank id ( |
|
All data set to |
|
Return |
|
Return the vector |
|
Return a pointer to the first element of block |
|
Return the number of blocks owned by the local rank. |
|
Broadcast data of block |
|
Broadcast the data of all blocks from their owner to all other ranks. |
|
Send block |
|
MPI Gather all blocks from their owner at rank |